Deep Learning for Graphics Programmers: Performing Tensor Operations with DirectML and Direct3D 12
Deep Learning for Graphics Programmers: Performing Tensor Operations with DirectML and Direct3D 12
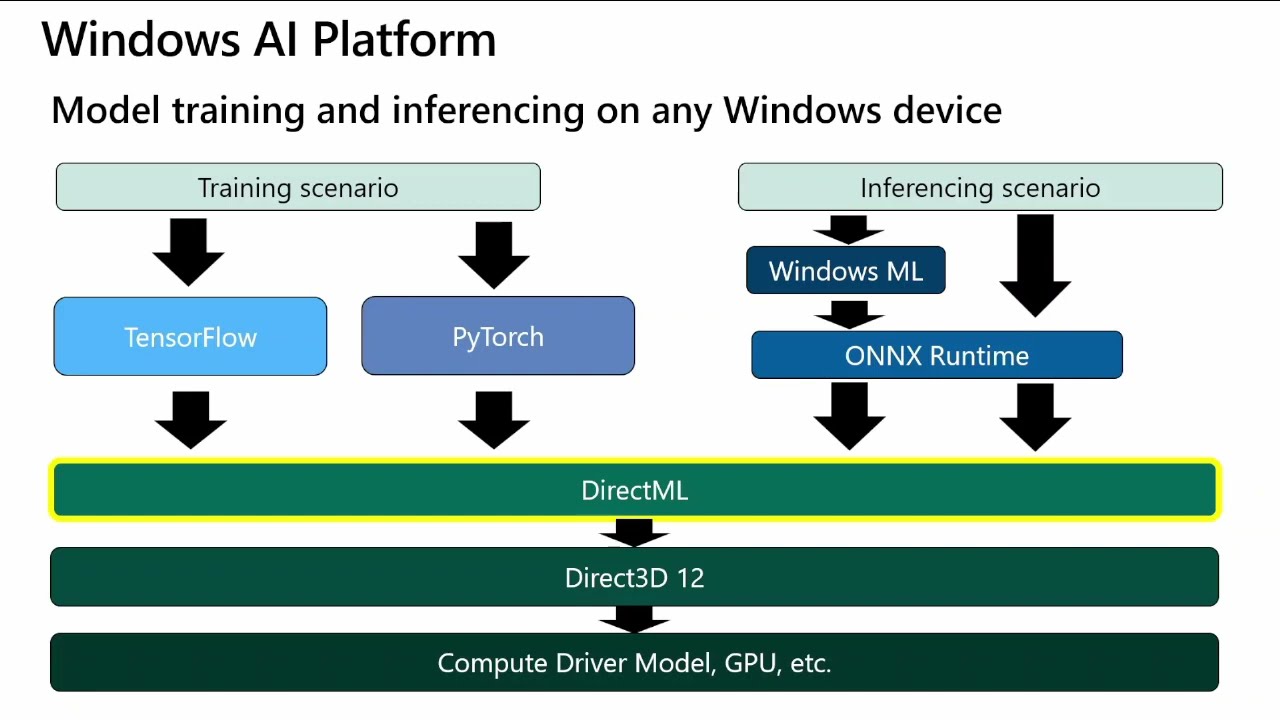
In the rapidly evolving landscape of machine learning and artificial intelligence, harnessing the power of modern GPUs is essential for achieving high-performance computations. DirectML (Direct Machine Learning) is an exciting library that allows developers to leverage GPU acceleration for machine learning tasks on Windows. Built on top of Direct3D 12, DirectML provides a hardware-agnostic, high-performance, and flexible framework for running machine learning models on a wide range of GPU hardware.
What is DirectML?
DirectML is a low-level machine learning API designed by Microsoft that allows developers to run machine learning operations on GPUs using Direct3D 12. It is part of the Windows AI Platform and integrates seamlessly with existing DirectX technologies, enabling high-performance, GPU-accelerated machine learning workloads.
Key Features of DirectML:
-
Hardware Agnostic: DirectML works across various GPU hardware, including those from NVIDIA, AMD, and Intel, making it a versatile choice for developers targeting different platforms.
-
High Performance: By leveraging the power of Direct3D 12, DirectML provides low-level control over GPU resources, ensuring high performance and efficiency.
-
Flexibility: DirectML supports a wide range of machine learning operations and can be integrated into custom machine learning pipelines or existing frameworks.
-
Interoperability: DirectML can work alongside other DirectX technologies, making it easy to integrate into graphics and compute applications.
Getting Started with DirectML
To get started with DirectML, you need a basic understanding of Direct3D 12, as DirectML builds on top of it. Here’s a simplified overview of the steps involved in using DirectML for a machine learning task:
1. Create a New Project
- Open Visual Studio.
- Select File > New > Project.
- Choose Console App (or Empty Project if you prefer) from the list.
- Name your project (e.g.,
DirectML) and click Create.
2. Add Necessary Files
- Right-click on the Source Files folder in the Solution Explorer.
- Select Add > New Item.
- Choose C++ File (.cpp) and name it (e.g.,
main.cpp).
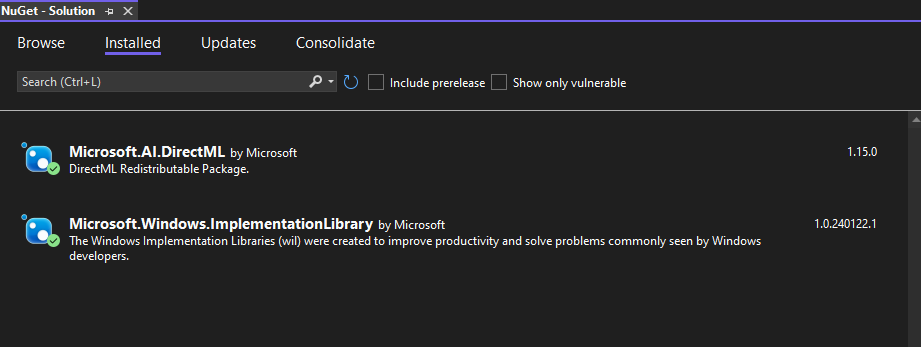
3. Install DirectML
- Open the NuGet Package Manager by right-clicking on your project in the Solution Explorer and selecting Manage NuGet Packages.
- Search for and install the Microsoft.AI.DirectML package.
4. Set Up Project Properties
- Right-click on your project in the Solution Explorer and select Properties.
General Settings
- Go to Configuration Properties > General.
- Set Platform Toolset to the version of your Visual Studio (e.g.,
v142for VS 2019).
VC++ Directories
- Go to Configuration Properties > VC++ Directories.
- Add the include and library directories for DirectX and DirectML:
- Include Directories: Add
$(DXSDK_DIR)\Includeand$(VCInstallDir)Include. - Library Directories: Add
$(DXSDK_DIR)\Lib\x64(orx86if you’re targeting 32-bit) and$(VCInstallDir)Lib.
- Include Directories: Add
Linker Settings
- Go to Configuration Properties > Linker > Input.
- Add the following libraries to the Additional Dependencies:
d3d12.libdxgi.libd3dcompiler.libDirectML.lib
Preprocessor Definitions
- Go to Configuration Properties > C/C++ > Preprocessor.
- Add
D3DX12_NO_STATE_OBJECT_HELPERSto Preprocessor Definitions if you’re using thed3dx12.hheader file.
5. Include DirectX Helper Files
- Download
d3dx12.hfrom the DirectX-Headers GitHub repository: https://github.com/microsoft/DirectX-Headers/blob/main/include/directx/d3dx12.h. - Add
d3dx12.hto your project by right-clicking on the Header Files folder in the Solution Explorer, selecting Add > Existing Item, and choosing thed3dx12.hfile.
Code Walkthrough
Header File: pch.h
The pch.h file serves as the precompiled header file for the project. It includes essential libraries and headers required for the Direct3D 12 and DirectML operations. The purpose of a precompiled header is to speed up the compilation process by compiling the listed headers only once and reusing the compiled code in subsequent builds. Here’s a breakdown of what each included library and header contributes:
-
Standard Libraries: Includes libraries such as
<algorithm>,<array>,<cstdint>,<cassert>,<fstream>,<iostream>,<iterator>,<vector>, and<optional>. These provide basic functionalities like array manipulation, file handling, input/output operations, and more. -
WIL Libraries:
wil/result.handwil/resource.hfrom the Windows Implementation Libraries (WIL) simplify resource management and error handling, making the code more robust and readable. -
Direct3D 12 and DirectML Headers:
d3dx12_xs.handd3d12_xs.hare essential for Direct3D 12 operations.d3dx12.his a helper library that simplifies common tasks in Direct3D 12, reducing boilerplate code.dxgi1_4.his for the DirectX Graphics Infrastructure (DXGI), which handles enumerating graphics adapters and monitors.DirectML.his the DirectML header from the Windows SDK, enabling the use of machine learning features.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
// Copyright (c) Microsoft Corporation. All rights reserved.
// Licensed under the MIT License.
#pragma once
#include <wil/result.h>
#include <wil/resource.h>
#include <algorithm>
#include <array>
#include <cstdint>
#include <cassert>
#include <fstream>
#include <iostream>
#include <iterator>
#include <vector>
#include <optional>
#include <d3dx12_xs.h>
#include <d3d12_xs.h>
#include "d3dx12.h" // The D3D12 Helper Library that you downloaded.
#include <dxgi1_4.h>
#include <DirectML.h> // The DirectML header from the Windows SDK.
1. Direct3D 12 Initialization
The first step in utilizing DirectML is initializing the Direct3D 12 components. Direct3D 12 is a low-level graphics API that provides developers with control over GPU operations. Initialization involves enabling the debug layer, creating the Direct3D 12 device, command queue, command allocator, and command list. The debug layer is essential for development as it provides detailed error messages that aid in debugging. The device represents the virtual adapter and manages resources, while the command queue is responsible for sending commands to the GPU. The command allocator and command list work together to record and manage commands that will be executed by the GPU.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
#include "pch.h"
using Microsoft::WRL::ComPtr;
void InitializeDirect3D12(
ComPtr<ID3D12Device> & d3D12Device,
ComPtr<ID3D12CommandQueue> & commandQueue,
ComPtr<ID3D12CommandAllocator> & commandAllocator,
ComPtr<ID3D12GraphicsCommandList> & commandList) {
ComPtr<ID3D12Debug> d3D12Debug;
THROW_IF_FAILED(D3D12GetDebugInterface(IID_PPV_ARGS(d3D12Debug.GetAddressOf())));
d3D12Debug->EnableDebugLayer();
ComPtr<IDXGIFactory4> dxgiFactory;
THROW_IF_FAILED(CreateDXGIFactory1(IID_PPV_ARGS(dxgiFactory.GetAddressOf())));
ComPtr<IDXGIAdapter> dxgiAdapter;
UINT adapterIndex = 0;
HRESULT hr;
do {
dxgiAdapter = nullptr;
THROW_IF_FAILED(dxgiFactory->EnumAdapters(adapterIndex, dxgiAdapter.ReleaseAndGetAddressOf()));
++adapterIndex;
hr = ::D3D12CreateDevice(dxgiAdapter.Get(), D3D_FEATURE_LEVEL_11_0, IID_PPV_ARGS(d3D12Device.ReleaseAndGetAddressOf()));
if (hr == DXGI_ERROR_UNSUPPORTED) continue;
THROW_IF_FAILED(hr);
} while (hr != S_OK);
D3D12_COMMAND_QUEUE_DESC commandQueueDesc = {};
commandQueueDesc.Type = D3D12_COMMAND_LIST_TYPE_DIRECT;
commandQueueDesc.Flags = D3D12_COMMAND_QUEUE_FLAG_NONE;
THROW_IF_FAILED(d3D12Device->CreateCommandQueue(&commandQueueDesc, IID_GRAPHICS_PPV_ARGS(commandQueue.ReleaseAndGetAddressOf())));
THROW_IF_FAILED(d3D12Device->CreateCommandAllocator(D3D12_COMMAND_LIST_TYPE_DIRECT, IID_GRAPHICS_PPV_ARGS(commandAllocator.ReleaseAndGetAddressOf())));
THROW_IF_FAILED(d3D12Device->CreateCommandList(0, D3D12_COMMAND_LIST_TYPE_DIRECT, commandAllocator.Get(), nullptr, IID_GRAPHICS_PPV_ARGS(commandList.ReleaseAndGetAddressOf())));
}
2. DirectML Device and Operator Initialization
With Direct3D 12 initialized, the next step is creating the DirectML device. This device acts as an interface for executing machine learning operations on the GPU. The device creation involves specifying any flags necessary for the DirectML device, although typically, no special flags are needed. Creating the DirectML device sets the stage for defining and executing machine learning operators.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
int main() {
ComPtr<ID3D12Device> d3D12Device;
ComPtr<ID3D12CommandQueue> commandQueue;
ComPtr<ID3D12CommandAllocator> commandAllocator;
ComPtr<ID3D12GraphicsCommandList> commandList;
// Initialize Direct3D 12.
InitializeDirect3D12(d3D12Device, commandQueue, commandAllocator, commandList);
// Create the DirectML device.
DML_CREATE_DEVICE_FLAGS dmlCreateDeviceFlags = DML_CREATE_DEVICE_FLAG_NONE;
ComPtr<IDMLDevice> dmlDevice;
THROW_IF_FAILED(DMLCreateDevice(d3D12Device.Get(), dmlCreateDeviceFlags, IID_PPV_ARGS(dmlDevice.GetAddressOf())));
// Define tensor sizes and properties.
constexpr UINT tensorSizes[4] = { 1, 2, 3, 4 };
constexpr UINT tensorElementCount = tensorSizes[0] * tensorSizes[1] * tensorSizes[2] * tensorSizes[3];
DML_BUFFER_TENSOR_DESC dmlBufferTensorDesc = {};
dmlBufferTensorDesc.DataType = DML_TENSOR_DATA_TYPE_FLOAT32;
dmlBufferTensorDesc.Flags = DML_TENSOR_FLAG_NONE;
dmlBufferTensorDesc.DimensionCount = ARRAYSIZE(tensorSizes);
dmlBufferTensorDesc.Sizes = tensorSizes;
dmlBufferTensorDesc.TotalTensorSizeInBytes = DMLCalcBufferTensorSize(dmlBufferTensorDesc.DataType, dmlBufferTensorDesc.DimensionCount, dmlBufferTensorDesc.Sizes, nullptr);
3. Define and Create DirectML Operator
Once the tensor is defined, the next step is to define and create a DirectML operator. Operators represent the mathematical operations performed on tensors. In this guide, we use the Identity operator, which outputs the same value as the input tensor. Defining the operator involves specifying the input and output tensor descriptions, and creating the operator using the DirectML device. This operator will be compiled into a form that can be executed on the GPU.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// Define and create a DirectML operator (Identity operator).
ComPtr<IDMLOperator> dmlOperator;
DML_TENSOR_DESC dmlTensorDesc = {};
dmlTensorDesc.Type = DML_TENSOR_TYPE_BUFFER;
dmlTensorDesc.Desc = &dmlBufferTensorDesc;
DML_ELEMENT_WISE_IDENTITY_OPERATOR_DESC dmlIdentityOperatorDesc = {};
dmlIdentityOperatorDesc.InputTensor = &dmlTensorDesc;
dmlIdentityOperatorDesc.OutputTensor = &dmlTensorDesc;
DML_OPERATOR_DESC dmlOperatorDesc = {};
dmlOperatorDesc.Type = DML_OPERATOR_ELEMENT_WISE_IDENTITY;
dmlOperatorDesc.Desc = &dmlIdentityOperatorDesc;
THROW_IF_FAILED(dmlDevice->CreateOperator(&dmlOperatorDesc, IID_PPV_ARGS(dmlOperator.GetAddressOf())));
4. Compile the Operator
Once the tensor is defined, the next step is to define and create a DirectML operator. Operators represent the mathematical operations performed on tensors. In this guide, we use the Identity operator, which outputs the same value as the input tensor. Defining the operator involves specifying the input and output tensor descriptions, and creating the operator using the DirectML device. This operator will be compiled into a form that can be executed on the GPU.
1
2
3
// Compile the operator.
ComPtr<IDMLCompiledOperator> dmlCompiledOperator;
THROW_IF_FAILED(dmlDevice->CompileOperator(dmlOperator.Get(), DML_EXECUTION_FLAG_NONE, IID_PPV_ARGS(dmlCompiledOperator.GetAddressOf())));
5. Create Descriptor Heap and Binding Table
After compiling the operator, the next step is to create a descriptor heap and binding table. The descriptor heap is a GPU resource that stores descriptors, which are references to resources such as buffers and textures. The binding table maps these descriptors to the inputs and outputs of the compiled operator. This setup allows the GPU to access the necessary resources during execution.
1
2
3
4
5
6
7
8
9
10
11
// Create descriptor heap and binding table.
ComPtr<ID3D12DescriptorHeap> descriptorHeap;
D3D12_DESCRIPTOR_HEAP_DESC descriptorHeapDesc = {};
descriptorHeapDesc.Type = D3D12_DESCRIPTOR_HEAP_TYPE_CBV_SRV_UAV;
descriptorHeapDesc.NumDescriptors = 1;
descriptorHeapDesc.Flags = D3D12_DESCRIPTOR_HEAP_FLAG_SHADER_VISIBLE;
THROW_IF_FAILED(d3D12Device->CreateDescriptorHeap(&descriptorHeapDesc, IID_GRAPHICS_PPV_ARGS(descriptorHeap.GetAddressOf())));
// Set the descriptor heap(s).
ID3D12DescriptorHeap* d3D12DescriptorHeaps[] = { descriptorHeap.Get() };
commandList->SetDescriptorHeaps(ARRAYSIZE(d3D12DescriptorHeaps), d3D12DescriptorHeaps);
6. Initialize and Execute the Operator
With the binding table set up, it’s time to initialize and execute the operator. This step involves creating and uploading input tensor data to the GPU. The input data is typically stored in a buffer, which is then bound to the binding table. The operator is executed by recording commands in the command list and dispatching them to the command queue. Execution involves specifying the root signature, descriptor table, and dispatching the compute shader to process the data.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
// Create and initialize binding table.
DML_BINDING_TABLE_DESC dmlBindingTableDesc = {};
dmlBindingTableDesc.Dispatchable = dmlCompiledOperator.Get();
dmlBindingTableDesc.CPUDescriptorHandle = descriptorHeap->GetCPUDescriptorHandleForHeapStart();
dmlBindingTableDesc.GPUDescriptorHandle = descriptorHeap->GetGPUDescriptorHandleForHeapStart();
dmlBindingTableDesc.SizeInDescriptors = 1;
ComPtr<IDMLBindingTable> dmlBindingTable;
THROW_IF_FAILED(dmlDevice->CreateBindingTable(&dmlBindingTableDesc, IID_PPV_ARGS(dmlBindingTable.GetAddressOf())));
// Create tensor buffers.
ComPtr<ID3D12Resource> uploadBuffer, inputBuffer, outputBuffer;
UINT64 tensorBufferSize = dmlBufferTensorDesc.TotalTensorSizeInBytes;
// Create and upload input tensor data.
THROW_IF_FAILED(d3D12Device->CreateCommittedResource(&CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_UPLOAD), D3D12_HEAP_FLAG_NONE, &CD3DX12_RESOURCE_DESC::Buffer(tensorBufferSize), D3D12_RESOURCE_STATE_GENERIC_READ, nullptr, IID_GRAPHICS_PPV_ARGS(uploadBuffer.GetAddressOf())));
THROW_IF_FAILED(d3D12Device->CreateCommittedResource(&CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_DEFAULT), D3D12_HEAP_FLAG_NONE, &CD3DX12_RESOURCE_DESC::Buffer(tensorBufferSize, D3D12_RESOURCE_FLAG_ALLOW_UNORDERED_ACCESS), D3D12_RESOURCE_STATE_COPY_DEST, nullptr, IID_GRAPHICS_PPV_ARGS(inputBuffer.GetAddressOf())));
std::array<FLOAT, tensorElementCount> inputTensorElementArray;
for (auto &element : inputTensorElementArray) {
element = 1.618f;
}
D3D12_SUBRESOURCE_DATA tensorSubresourceData = {};
tensorSubresourceData.pData = inputTensorElementArray.data();
tensorSubresourceData.RowPitch = static_cast<LONG_PTR>(tensorBufferSize);
tensorSubresourceData.SlicePitch = tensorSubresourceData.RowPitch;
// Upload the input tensor to the GPU.
::UpdateSubresources(commandList.Get(), inputBuffer.Get(), uploadBuffer.Get(), 0, 0, 1, &tensorSubresourceData);
commandList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(inputBuffer.Get(), D3D12_RESOURCE_STATE_COPY_DEST, D3D12_RESOURCE_STATE_UNORDERED_ACCESS));
// Bind input and output buffers to the binding table.
DML_BUFFER_BINDING inputBufferBinding = { inputBuffer.Get(), 0, tensorBufferSize };
DML_BINDING_DESC inputBindingDesc = { DML_BINDING_TYPE_BUFFER, &inputBufferBinding };
dmlBindingTable->BindInputs(1, &inputBindingDesc);
THROW_IF_FAILED(d3D12Device->CreateCommittedResource(&CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_DEFAULT), D3D12_HEAP_FLAG_NONE, &CD3DX12_RESOURCE_DESC::Buffer(tensorBufferSize, D3D12_RESOURCE_FLAG_ALLOW_UNORDERED_ACCESS), D3D12_RESOURCE_STATE_UNORDERED_ACCESS, nullptr, IID_GRAPHICS_PPV_ARGS(outputBuffer.GetAddressOf())));
DML_BUFFER_BINDING output
BufferBinding = { outputBuffer.Get(), 0, tensorBufferSize };
DML_BINDING_DESC outputBindingDesc = { DML_BINDING_TYPE_BUFFER, &outputBufferBinding };
dmlBindingTable->BindOutputs(1, &outputBindingDesc);
7. Execute the Operator and Read Back Results
Once the operator is dispatched, it’s necessary to wait for the GPU to complete execution. This is achieved by using a fence, a synchronization primitive that allows the CPU to wait for the GPU to reach a certain point in its command queue. After the GPU finishes execution, the results are copied from the GPU to a readback buffer on the CPU. This buffer is mapped to access the output tensor data, which can then be read and processed by the application.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
// Record commands to execute the operator.
commandList->SetComputeRootSignature(dmlDevice->GetRootSignature());
commandList->SetComputeRootDescriptorTable(0, descriptorHeap->GetGPUDescriptorHandleForHeapStart());
commandList->Dispatch(1, 1, 1);
// Prepare and execute command list.
THROW_IF_FAILED(commandList->Close());
ID3D12CommandList* commandLists[] = { commandList.Get() };
commandQueue->ExecuteCommandLists(ARRAYSIZE(commandLists), commandLists);
// Wait for GPU to finish.
ComPtr<ID3D12Fence> fence;
THROW_IF_FAILED(d3D12Device->CreateFence(0, D3D12_FENCE_FLAG_NONE, IID_PPV_ARGS(fence.GetAddressOf())));
HANDLE event = CreateEvent(nullptr, FALSE, FALSE, nullptr);
THROW_IF_FAILED(commandQueue->Signal(fence.Get(), 1));
THROW_IF_FAILED(fence->SetEventOnCompletion(1, event));
WaitForSingleObject(event, INFINITE);
CloseHandle(event);
// Copy the results from GPU to CPU.
ComPtr<ID3D12Resource> readbackBuffer;
THROW_IF_FAILED(d3D12Device->CreateCommittedResource(&CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_READBACK), D3D12_HEAP_FLAG_NONE, &CD3DX12_RESOURCE_DESC::Buffer(tensorBufferSize), D3D12_RESOURCE_STATE_COPY_DEST, nullptr, IID_GRAPHICS_PPV_ARGS(readbackBuffer.GetAddressOf())));
commandList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(outputBuffer.Get(), D3D12_RESOURCE_STATE_UNORDERED_ACCESS, D3D12_RESOURCE_STATE_COPY_SOURCE));
commandList->CopyResource(readbackBuffer.Get(), outputBuffer.Get());
THROW_IF_FAILED(commandList->Close());
commandQueue->ExecuteCommandLists(ARRAYSIZE(commandLists), commandLists);
// Map and read back the output tensor data.
FLOAT* outputTensorData;
THROW_IF_FAILED(readbackBuffer->Map(0, nullptr, reinterpret_cast<void**>(&outputTensorData)));
for (UINT i = 0; i < tensorElementCount; ++i) {
std::cout << outputTensorData[i] << " ";
}
readbackBuffer->Unmap(0, nullptr);
return 0;
}
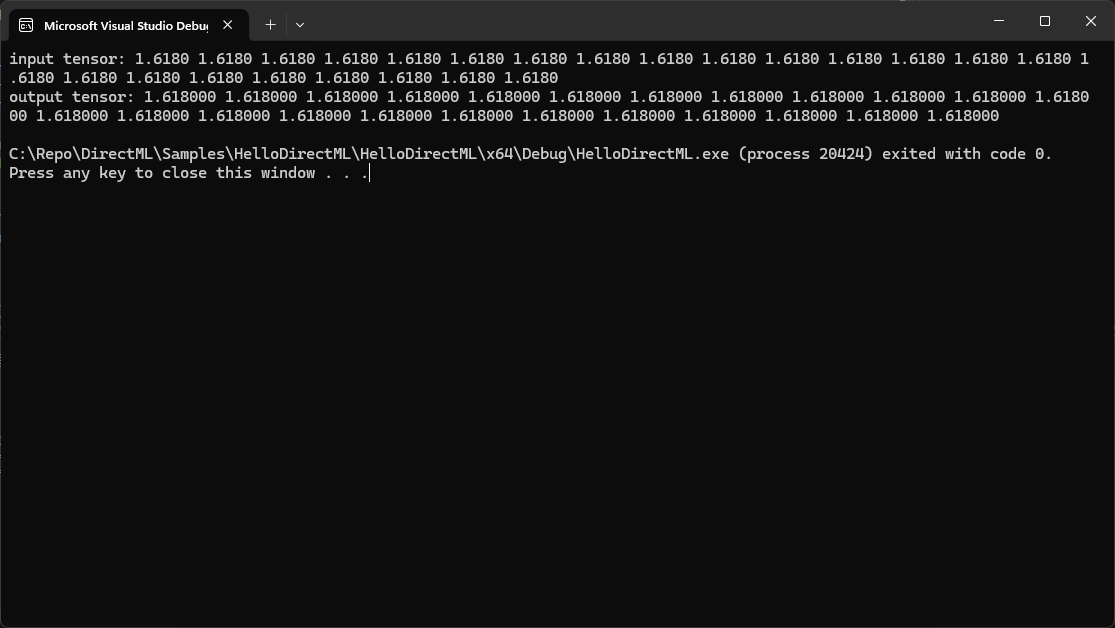
Last Thought
Performing tensor operations using DirectML and Direct3D 12 involves several steps, from initializing Direct3D 12 components to executing and reading back results. Each step is crucial for ensuring efficient and correct execution of machine learning operations on the GPU. By following this guide, developers can leverage the power of DirectML and Direct3D 12 to perform high-performance tensor operations, enabling advanced machine learning applications on Windows.