
In the realm of PyTorch model benchmarking, achieving accurate results is paramount for gauging performance effectively. However, traditional benchmarking often overlooks the initial warmup phase, leading to skewed results. In this article, we explore the importance of accounting for warmup iterations and techniques to calculate correct benchmark results for PyTorch models.
Understanding the Impact of Warmup
Warmup iterations are crucial in PyTorch model benchmarking as they allow the model and the computational environment to stabilize. Initially, factors such as JIT compilation, resource allocation, and data loading overhead significantly affect performance. Ignoring these warmup iterations can lead to misleading benchmark results, as subsequent iterations reflect the stabilized performance.
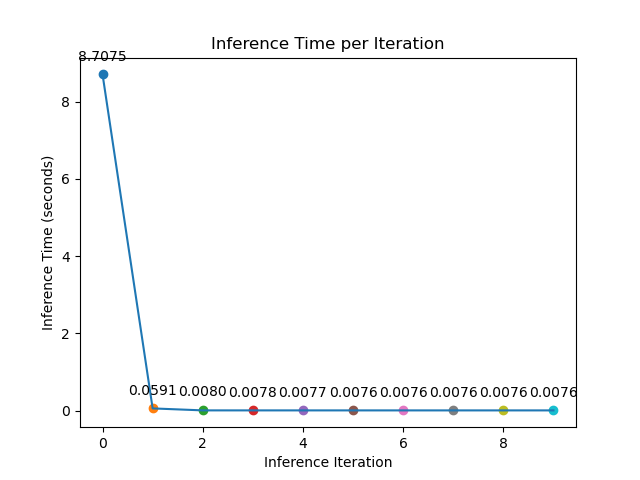
This figure underscores the necessity of warmup iterations for accurate benchmarking. The initial warmup overhead significantly affects the first iteration, but subsequent iterations stabilize to a lower and consistent level. By discarding warmup iterations and analyzing the stabilized performance, we can obtain reliable benchmark results for PyTorch models.
Strategies for Correct Benchmarking
To calculate accurate benchmark results, it’s essential to account for warmup iterations. Here are some strategies to achieve this:
- Initial Discard: Ignore a predetermined number of initial iterations to eliminate warmup effects. These discarded iterations represent the warmup phase and should not be considered for benchmarking analysis.
- Statistical Analysis: Perform statistical analysis on the remaining iterations to calculate accurate benchmark results. Calculate metrics such as mean, median, standard deviation, etc., to obtain a reliable estimate of the model’s performance.
- Warmup Identification: Profile the model’s performance during warmup iterations to identify the point where performance stabilizes. This helps in determining the number of warmup iterations to discard for accurate benchmarking.
Implementation in PyTorch: Let’s demonstrate how normal benchmark looks in PyTorch:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
import time
import torch
import intel_extension_for_pytorch as ipex
num_inference = 10
total_inference_time = 0
input_data = torch.randn(1, 3, 224, 224) # Replace with your input data
input_data=input_data.to("xpu") # Using Intel GPU
model = torch.jit.load('Resnet.pt')
model=model.to("xpu") # Using Intel GPU
model = ipex.optimize(model) # Using Intel GPU
model.eval()
for _ in range(num_inference):
with torch.no_grad():
start_time = time.time()
expected_output = model(input_data)
end_time = time.time()
inference_time = end_time - start_time
total_inference_time += inference_time
average_inference_time = total_inference_time / num_inference
Implementation in PyTorch: Let’s demonstrate how to implement correct benchmarking in PyTorch:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# Similar Code from Above
# Warmup phase
for i in range(3): # Perform 3 warmup iterations
_ = model(input_data)
for _ in range(num_inference):
with torch.no_grad():
start_time = time.time()
expected_output = model(input_data)
end_time = time.time()
inference_time = end_time - start_time
total_inference_time += inference_time
average_inference_time = total_inference_time / num_inference
By running both versions of inference, you can observe the impact of warmup on the execution times and the stability of the results. Warmup inference should stabilize after a few initial iterations, leading to more consistent performance metrics.