
Comparing SYCL, OpenCL, and CUDA: Matrix Multiplication Example
Matrix multiplication is a core operation in scientific and engineering applications, often accelerated using specialized programming models like SYCL, OpenCL, and CUDA. These models leverage GPUs for parallel computation. Let’s delve into how matrix multiplication is implemented in each framework and compare their approaches.
Overview
| Feature | SYCL | OpenCL | CUDA |
|---|---|---|---|
| Language | C++ | C, C++ | C, C++ |
| Hardware | CPUs, GPUs, FPGAs | CPUs, GPUs, FPGAs, DSPs | NVIDIA GPUs |
| Portability | High, built on OpenCL | High, open standard | Low, NVIDIA GPUs only |
| Ease of Use | High, modern C++ | Moderate, requires knowledge of parallel computing | High, optimized with a learning curve |
CUDA
CUDA, developed by NVIDIA, is a widely used parallel computing platform and programming model for NVIDIA GPUs.
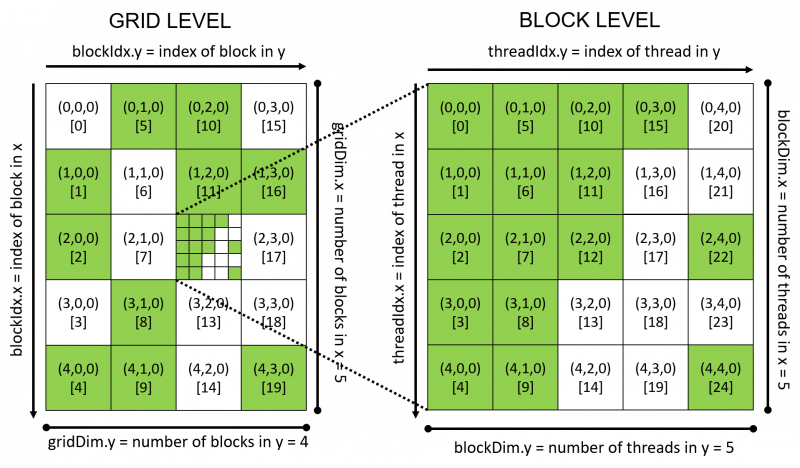
In CUDA programming, efficient GPU utilization involves understanding threads, blocks, and grids:
Threads
A thread is the smallest unit of execution in CUDA. Each thread executes the same kernel function independently, but with different data. Threads within the same block can cooperate via shared memory and synchronization mechanisms.
Blocks
A block is a group of threads that execute the same kernel code simultaneously. Threads within a block can synchronize with each other and share data through shared memory.
- Block Dimensions: Each block can have a maximum of 1,024 threads (as of CUDA capability 7.x). Blocks are organized in three dimensions (x, y, and z), allowing up to 1,024 threads per block in each dimension. The total number of threads in a block (blockDim.x * blockDim.y * blockDim.z) should not exceed the maximum block size supported by the GPU architecture.
Grids
A grid is a collection of blocks that execute the kernel function. Blocks in a grid can execute independently of each other and are scheduled on streaming multiprocessors (SMs) of the GPU.
- Grid Dimensions: Grids are also organized in three dimensions (x, y, and z), allowing up to 65,535 blocks per grid dimension (gridDim.x, gridDim.y, and gridDim.z). The total number of blocks in a grid (gridDim.x * gridDim.y * gridDim.z) depends on the computation and the available resources on the GPU.
Relationship and Usage
Thread Indexing
Each thread within a grid has a unique index (threadIdx.x, threadIdx.y, threadIdx.z) that identifies its position within its block.
Block Indexing
Each block within a grid has a unique index (blockIdx.x, blockIdx.y, blockIdx.z) that identifies its position within the grid.
Grid Configuration
When launching a kernel, you specify the dimensions of the grid and the dimensions of each block (dim3 type in CUDA). This configuration determines how the kernel threads are organized and executed on the GPU.
CUDA Matrix Multiplication Example
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
#include <cuda_runtime.h>
#include <iostream>
__global__ void matrixMul(float *A, float *B, float *C, int N) {
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
if (row < N && col < N) {
float sum = 0.0f;
for (int i = 0; i < N; ++i) {
sum += A[row * N + i] * B[i * N + col];
}
C[row * N + col] = sum;
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
int main() {
const int N = 1024;
float *h_A, *h_B, *h_C;
float *d_A, *d_B, *d_C;
size_t size = N * N * sizeof(float);
// Allocate memory on host
h_A = (float*)malloc(size);
h_B = (float*)malloc(size);
h_C = (float*)malloc(size);
// Initialize matrices h_A and h_B
// ...
// Allocate memory on device
cudaMalloc(&d_A, size);
cudaMalloc(&d_B, size);
cudaMalloc(&d_C, size);
// Copy matrices from host to device
cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
// Define grid and block dimensions
dim3 blockSize(16, 16);
dim3 gridSize((N + blockSize.x - 1) / blockSize.x, (N + blockSize.y - 1) / blockSize.y);
// Launch kernel
matrixMul<<<gridSize, blockSize>>>(d_A, d_B, d_C, N);
// Copy result matrix from device to host
cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
return 0;
}
OpenCL
OpenCL is an open standard for parallel programming of heterogeneous systems, supporting CPUs, GPUs, and FPGAs.
OpenCL Matrix Multiplication Example
1
2
3
#include <CL/cl.h>
#include <iostream>
#define MAX_SOURCE_SIZE (0x100000)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
int main() {
const int N = 1024;
float *h_A, *h_B, *h_C;
cl_mem d_A, d_B, d_C;
cl_platform_id platform_id = NULL;
cl_device_id device_id = NULL;
cl_context context = NULL;
cl_command_queue command_queue = NULL;
cl_program program = NULL;
cl_kernel kernel = NULL;
cl_uint ret_num_devices;
cl_uint ret_num_platforms;
cl_int ret;
size_t size = N * N * sizeof(float);
h_A = (float*)malloc(size);
h_B = (float*)malloc(size);
h_C = (float*)malloc(size);
// Initialize matrices h_A and h_B
// ...
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// Get platform and device information
ret = clGetPlatformIDs(1, &platform_id, &ret_num_platforms);
ret = clGetDeviceIDs(platform_id, CL_DEVICE_TYPE_GPU, 1, &device_id, &ret_num_devices);
// Create OpenCL context
context = clCreateContext(NULL, 1, &device_id, NULL, NULL, &ret);
// Create command queue
command_queue = clCreateCommandQueue(context, device_id, 0, &ret);
// Create memory buffers for matrices
d_A = clCreateBuffer(context, CL_MEM_READ_ONLY, size, NULL, &ret);
d_B = clCreateBuffer(context, CL_MEM_READ_ONLY, size, NULL, &ret);
d_C = clCreateBuffer(context, CL_MEM_WRITE_ONLY, size, NULL, &ret);
// Copy matrices from host to device
ret = clEnqueueWriteBuffer(command_queue, d_A, CL_TRUE, 0, size, h_A, 0, NULL, NULL);
ret = clEnqueueWriteBuffer(command_queue, d_B, CL_TRUE, 0, size, h_B, 0, NULL, NULL);
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
// Create and build the compute program
const char *source_str = "kernel void matrixMul(global float *A, global float *B, global float *C, int N) { "
" int row = get_global_id(0); "
" int col = get_global_id(1); "
" if (row < N && col < N) { "
" float sum = 0.0f; "
" for (int i = 0; i < N; ++i) { "
" sum += A[row * N + i] * B[i * N + col]; "
" } "
" C[row * N + col] = sum; "
" } "
"}
";
program = clCreateProgramWithSource(context, 1, (const char **)&source_str, NULL, &ret);
ret = clBuildProgram(program, 1, &device_id, NULL, NULL, NULL);
// Create the OpenCL kernel
kernel = clCreateKernel(program, "matrixMul", &ret);
clSetKernelArg(kernel, 0, sizeof(cl_mem), (void *)&d_A);
clSetKernelArg(kernel, 1, sizeof(cl_mem), (void *)&d_B);
clSetKernelArg(kernel, 2, sizeof(cl_mem), (void *)&d_C);
clSetKernelArg(kernel, 3, sizeof(int), (void *)&N);
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
// Execute the OpenCL kernel
size_t global_item_size[2] = {N, N};
size_t local_item_size[2] = {16, 16};
ret = clEnqueueNDRangeKernel(command_queue, kernel, 2, NULL, global_item_size, local_item_size, 0, NULL, NULL);
// Copy result matrix from device to host
ret = clEnqueueReadBuffer(command_queue, d_C, CL_TRUE, 0, size, h_C, 0, NULL, NULL);
// Clean up
ret = clFlush(command_queue);
ret = clFinish(command_queue);
ret = clReleaseKernel(kernel);
ret = clReleaseProgram(program);
ret = clReleaseMemObject(d_A);
ret = clReleaseMemObject(d_B);
ret = clReleaseMemObject(d_C);
ret = clReleaseCommandQueue(command_queue);
ret = clReleaseContext(context);
return 0;
}
SYCL
SYCL is a higher-level C++ programming model built on OpenCL, providing a more user-friendly approach to GPU programming.
SYCL Matrix Multiplication Example
1
2
3
4
5
6
7
8
9
10
11
12
#include <CL/sycl.hpp>
#include <iostream>
using namespace sycl;
int main() {
const int N = 1024;
float *h_A = new float[N * N];
float *h_B = new float[N * N];
float *h_C = new float[N * N];
// Initialize matrices h_A and h_B
// ...
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
// Create SYCL queue
queue q;
{
// Create buffers
buffer<float, 2> d_A(h_A, range<2>(N, N));
buffer<float, 2> d_B(h_B, range<2>(N, N));
buffer<float, 2> d_C(h_C, range<2>(N, N));
// Submit command group to queue
q.submit([&](handler &cgh) {
// Accessors
auto A = d_A.get_access<access::mode::read>(cgh);
auto B = d_B.get_access<access::mode::read>(cgh);
auto C = d_C.get_access<access::mode::write>(cgh);
// Kernel
cgh.parallel_for<class matrixMul>(range<2>(N, N), [=](id<2> index) {
int row = index[0];
int col = index[1];
float sum = 0.0f;
for (int i = 0; i < N; ++i) {
sum += A[row][i] * B[i][col];
}
C[row][col] = sum;
});
});
}
// Buffers go out of scope and data is copied back to host
Comparison
Programming Model
- CUDA: Directive-based approach with fine-grained GPU control.
- OpenCL: Runtime API for C-like parallel computations across various architectures.
- SYCL: Single-source C++ programming with simplified memory management.
Memory Management
- CUDA: Explicit allocation (
cudaMalloc,cudaMemcpy) and deallocation (cudaFree). - OpenCL: Command queue manages data transfer (
clEnqueueWriteBuffer,clEnqueueReadBuffer) and kernel execution. - SYCL: Automatic memory handling with C++ integration.
Ease of Use and Portability
- CUDA: High performance and NVIDIA GPU integration but less portable.
- OpenCL: Broad platform support but may require more optimization effort.
- SYCL: Combines OpenCL’s portability with easier C++ programming, ideal for maintainability.
Conclusion
Choosing between CUDA, OpenCL, and SYCL depends on performance needs, hardware availability, and developer expertise. CUDA excels in NVIDIA GPU performance, while OpenCL offers broader hardware support and SYCL provides a user-friendly C++ interface with portability.