
In this article, I’ll break down the layers of a ViT step by step with code snippets, and a dry run of each layer.
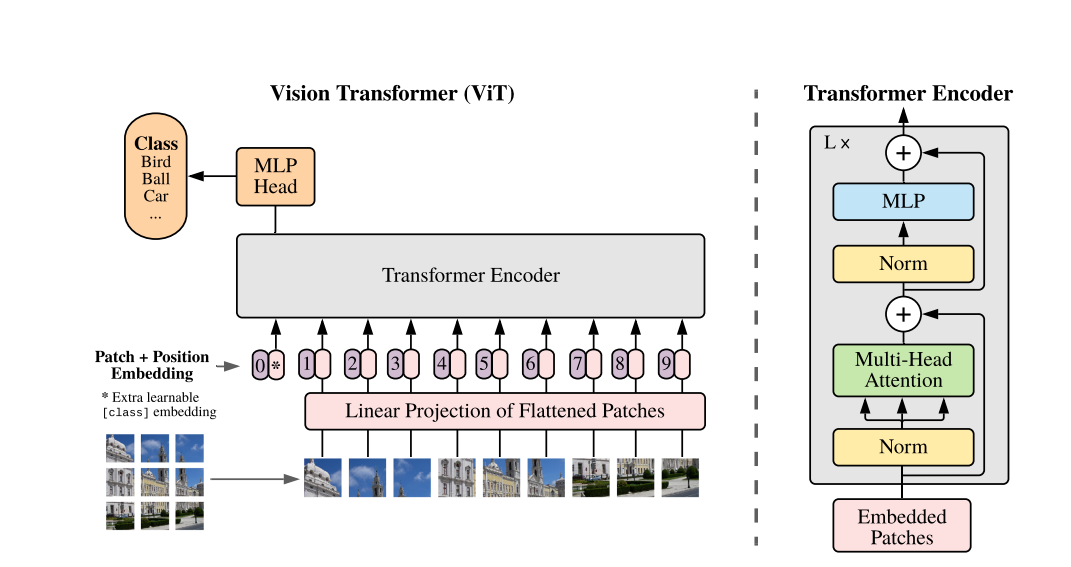
Overview of the Vision Transformer
ViT treats an image as a sequence of patches, just like words in a text sequence for natural language processing (NLP). The architecture consists of:
- Patch Embedding Layer: Converts image patches into embeddings.
- Positional Encoding: Adds positional information to patches.
- [CLS] Token: A special token to aggregate global information.
- Transformer Encoder Layers: Processes patches using multi-head self-attention and feedforward networks.
- Classification Head: Maps the processed embeddings to class probabilities.
Step-by-Step Implementation
1. Patch Embedding Layer
Split the image into non-overlapping patches, flatten them, and project each patch into a higher-dimensional embedding space.

Code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import torch
import torch.nn as nn
class PatchEmbedding(nn.Module):
def __init__(self, image_size, patch_size, embedding_dim):
super().__init__()
self.num_patches = (image_size // patch_size) ** 2
self.projection = nn.Conv2d(3, embedding_dim, kernel_size=patch_size, stride=patch_size)
self.flatten = nn.Flatten(2) # Flatten spatial dimensions
def forward(self, x):
x = self.projection(x) # Project image to patches
x = self.flatten(x) # Flatten spatial dimensions
x = x.transpose(1, 2) # Transpose to [batch_size, num_patches, embedding_dim]
return x
Dry Run:
- Input: Image of size
(3, 224, 224)(3 channels, 224x224 resolution). - Process:
- Divide into 16x16 patches → 224/16 X 224/16 = 196 patches.
- Flatten each patch and project to a 768-dimensional vector.
- Output: Tensor of shape
[batch_size, num_patches, embedding_dim]→[1, 196, 768].
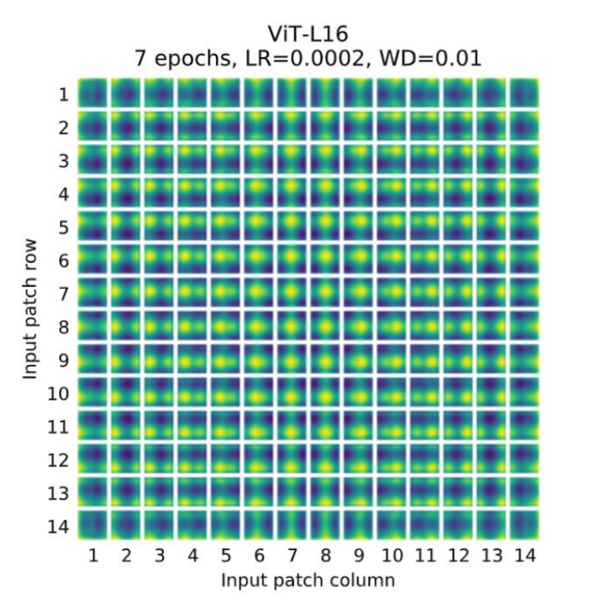
2. Positional Encoding
Purpose:
Since transformers lack inherent spatial information, positional encodings add context about where patches are located within the image.
Code:
1
2
3
4
5
6
7
class PositionalEncoding(nn.Module):
def __init__(self, num_patches, embedding_dim):
super().__init__()
self.positional_embedding = nn.Parameter(torch.randn(1, num_patches, embedding_dim))
def forward(self, x):
return x + self.positional_embedding
Dry Run:
- Input: Patch embeddings of shape
[1, 196, 768]. - Process: Add a learnable positional encoding to each patch.
- Output: Same shape
[1, 196, 768]but enriched with position information.
3. Adding the [CLS] Token
Purpose:
The [CLS] token acts as a placeholder for global image features, which will be used for classification.
Code:
1
2
3
4
5
6
7
8
9
class AddClsToken(nn.Module):
def __init__(self, embedding_dim):
super().__init__()
self.cls_token = nn.Parameter(torch.randn(1, 1, embedding_dim))
def forward(self, x):
batch_size = x.size(0)
cls_token = self.cls_token.expand(batch_size, -1, -1)
return torch.cat((cls_token, x), dim=1)
Dry Run:
- Input: Positional embeddings
[1, 196, 768]. - Process:
- Add
[CLS]token at the start of the sequence. - Resulting sequence length increases by 1 → 197.
- Add
- Output:
[1, 197, 768].
4. Transformer Encoder Layer
Purpose:
Performs attention-based processing on the sequence of patches to extract meaningful features. Each encoder layer consists of
Multi-Head Self-Attention: Allows patches to attend to each other.

Feedforward Network: Processes attended features.
Skip Connections: Adds stability and prevents vanishing gradients.
Code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
class TransformerEncoderBlock(nn.Module):
def __init__(self, embedding_dim, num_heads, ff_dim, dropout=0.1):
super().__init__()
self.attention = nn.MultiheadAttention(embedding_dim, num_heads, dropout=dropout)
self.norm1 = nn.LayerNorm(embedding_dim)
self.ff = nn.Sequential(
nn.Linear(embedding_dim, ff_dim),
nn.GELU(),
nn.Linear(ff_dim, embedding_dim)
)
self.norm2 = nn.LayerNorm(embedding_dim)
def forward(self, x):
# Self-attention with skip connection
attn_output, _ = self.attention(x, x, x)
x = self.norm1(x + attn_output)
# Feedforward with skip connection
ff_output = self.ff(x)
x = self.norm2(x + ff_output)
return x
Dry Run:
- Input:
[1, 197, 768]. - Process:
- Compute self-attention across patches.
- Pass through a feedforward network.
- Output:
[1, 197, 768].
5. Classification Head
Maps the [CLS] token to class probabilities for Dog and Cat.
Code:
1
2
3
4
5
6
7
8
class ClassificationHead(nn.Module):
def __init__(self, embedding_dim, num_classes):
super().__init__()
self.fc = nn.Linear(embedding_dim, num_classes)
def forward(self, x):
cls_output = x[:, 0] # Extract [CLS] token
return self.fc(cls_output)
Dry Run:
- Input:
[1, 197, 768]. - Process:
- Extract
[CLS]token. - Pass through a linear layer for classification.
- Extract
- Output:
[1, 2](logits for Dog and Cat).
6. Putting It All Together
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
class VisionTransformer(nn.Module):
def __init__(self, image_size, patch_size, embedding_dim, num_heads, ff_dim, num_classes, depth):
super().__init__()
self.patch_embedding = PatchEmbedding(image_size, patch_size, embedding_dim)
self.positional_encoding = PositionalEncoding((image_size // patch_size) ** 2, embedding_dim)
self.cls_token = AddClsToken(embedding_dim)
self.encoder = nn.Sequential(*[
TransformerEncoderBlock(embedding_dim, num_heads, ff_dim) for _ in range(depth)
])
self.classification_head = ClassificationHead(embedding_dim, num_classes)
def forward(self, x):
x = self.patch_embedding(x)
x = self.positional_encoding(x)
x = self.cls_token(x)
x = self.encoder(x)
return self.classification_head(x)
Final Thought
Built a Vision Transformer step by step for classifying. By replacing convolution with patch embeddings and using self-attention, ViT provides a powerful alternative to CNNs, especially for large-scale image datasets.
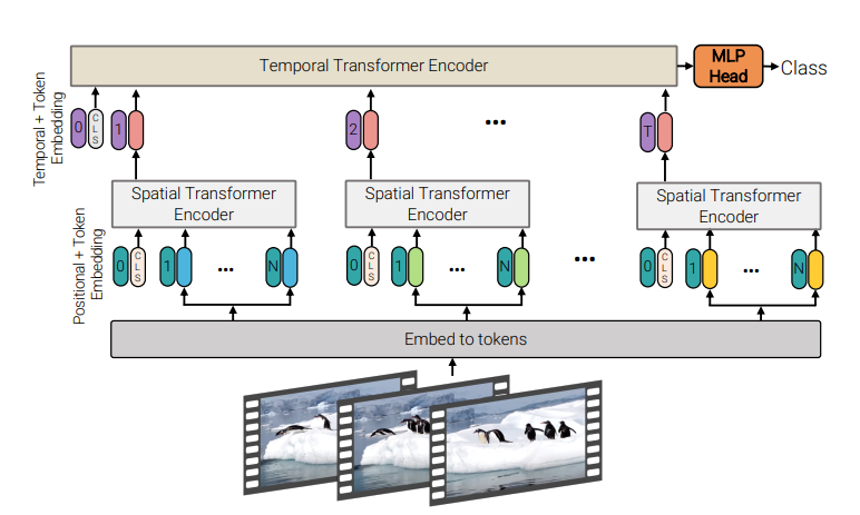
Next Advancement: Video Vision Transformers
Video Vision Transformers, an extension of the Vision Transformer (ViT) designed to handle video data. While ViT processes spatial information in images by dividing them into patches and modeling their relationships through self-attention, ViViT adds a temporal dimension to this process. It captures both spatial and temporal dependencies by extending the attention mechanism to include consecutive frames. This is achieved through techniques like dividing videos into spatiotemporal patches or applying 3D attention mechanisms. Will uncover this in next article
References
- Dosovitskiy, Alexey. “An image is worth 16x16 words: Transformers for image recognition at scale.” arXiv preprint arXiv:2010.11929 (2020).
- Arnab, Anurag, et al. “Vivit: A video vision transformer.” Proceedings of the IEEE/CVF international conference on computer vision. 2021.
- Yang, Yu-Qi, et al. “Swin3d: A pretrained transformer backbone for 3d indoor scene understanding.” arXiv preprint arXiv:2304.06906 (2023).